Designing a Threat Hunting Process and a SOC Management Platform based on MITRE ATT&CK and SPLUNK
Last March I attended the SplunkLive! 2020 event where Splunk and some of their clients shared their experience on using Splunk for system administration and security. It was a great experience and I learned a great deal in just a few hours spent there, so I decided to share with you some of the most important things I got from Splunk’s team and one of their clients’ SOC team – Bank of England’s. Here are all the lessons put together explaining you how to build a SOC environment and how to do threat hunting using Splunk.
This document explains how to design Threat Hunting and SOC Management using some security tools within Splunk, mainly based on the MITRE’s ATT&CK taxonomy and it answers to the following questions:
- How to implement a threat hunting process
- How to implement a SOC platform
- How to measure SOC effectiveness
- How to build dashboards and reports
SECTION I: How to Implement a Threat Hunting Process
1. Threat Hunting and Achieving Automated Detection
The threat hunting process should gravitate around automating attacks detection. A manual repeatable threat hunting runbook is not effective as it is slow, expensive, unreliable and doomed to fail regression tests. As such, any successful threat hunting attempts must be automated within the detection platform to allow handling automatically of any future attempts of using the same TTPs, no matter if they are tests or real threats.
In order to achieve automation, most of the focus should be placed on automating detection (75%) rather than investigating detections (25%) and the following operating model should be followed when splitting the effort:
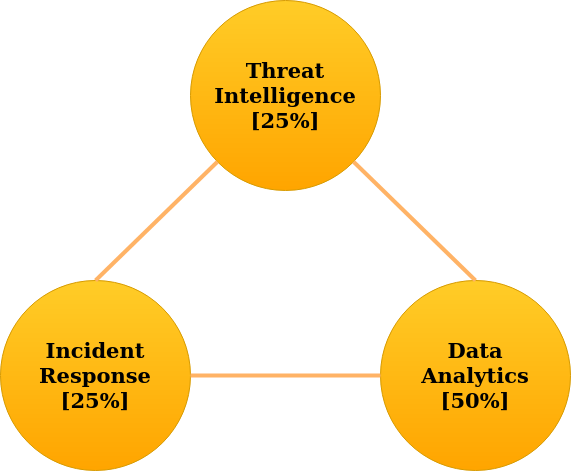
For this model to work, detection notifications have to cover all the information needed to triage them, rather than requiring additional effort to correlate them with other data before triage. If the same team is used for both threat hunting and incident response, the members can rotate through both responsibilities and add more information as needed in order to allow faster triage. If different teams are used, then the threat hunting team needs to take into account the feedback received from the incident response team to improve the detections. Both teams should decide on a change request mechanism and frequency/ prioritization.
2. Attack Threat Hunting Prioritization
Attacks should not be hunted randomly. Attack should be hunted based on the relevant APTs, new attacks for the relevant industry, common attacks and previous attacks targeting the company. As such, before starting any threat hunting activity, a list with the previous attacks and a list with the relevant APTs that apply to the finance and the blockchain industry have to be created. From here on, the Splunk Security Essentials (SSE) application can be used for prioritization.
The SSE application is able to filter all the MITRE attacks based on APTs and common attacks and provides pre-implemented detection algorithms (search strings) for identifying most of these threats, according to the MITRE detection specifications for each of those attacks. Moreover, SSE is able to show which of the detections can be enabled based on the data sources already ingested and what data sources are needed for each of the attacks to be able to enable the afferent detections.
Depending on the level of false positives generated by an alert, using SSE might be just enough or some additional logic may be needed to filter out the false positives.
Depending on the level of attack sophistication, testing preventive controls in place might be just enough (for the low sophistication attacks) or threat intelligence might be needed (for the high sophistication attacks).
3. The Anatomy of Handling a Single Attack
When handling a single attack, the following questions should be answered. Out of these 5 steps, threat hunting is concerned at least of the first 4 steps and incident response of the last 2 steps. They overlap on the “Triage Action” step, which is needed by threat hunters to provide actionable detections and by incident responders as input to decide on how to respond. Taken one step further, if the entire chain is automated, threat hunters are interested in the “Response Action” step as well, to provide full coverage.
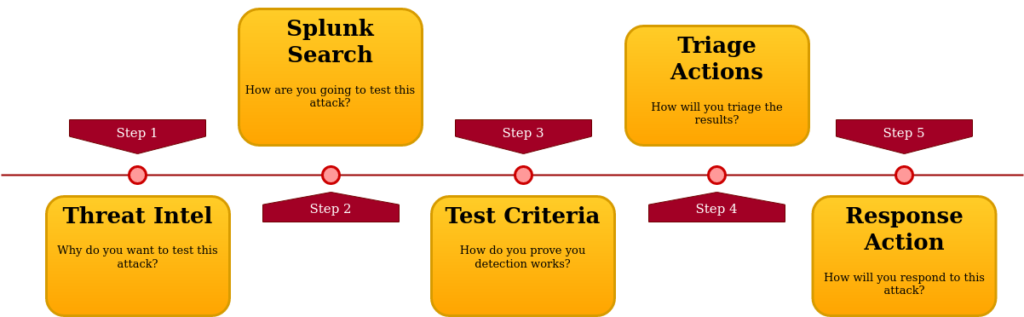
Several tools can be useful for handling attack detection and response in the following manner:
- SSE and attack prioritization as described in the previous section can be used to cover the threat intel step, along with various threat intelligence data sources for new relevant attacks or complex ones.
- there are 3 well-known applications in Splunk that come with predefined detection for the MITRE defined attacks: ES Content Update, SSE and ThreatHunting. The first 2 applications integrate well with Splunk Enterprise Security. The last one is an open-source library based on MITRE as well. All of them are good and they are recommended to be used in conjunction rather than limiting to only one of them. They can be used for the second step, to detect common attacks or APT specific attacks.
- the Atomic Red Team open-source library contains a series of tests ready to run for different platforms, based on the MITRE framework. They could be automated and run iteratively to test the detection in place works.
- for the MITRE attacks, the SSE application (possibly the other 2 as well) give comprehensive details and recommendations to triage them.
Finally, any new or complex attacks or more targeted ones should answer the same questions when hunted to provide reliable coverage. Otherwise, hunting it may be unjustified, undetectable and it may not provide the expected results. As for handling the MITRE attacks, some of them create many false alerts. The tools should be adjusted and more filtering should be added in place to reduce the level of noise.
SECTION II: How to implement a SOC platform
1. Threat Hunting and SOC Relationship
After an initial threat hunting process is in place to automatically detect potential threats, a platform should be designed for managing all the detection and to allow rapid triage. This is a SOC platform. Splunk ES comes with an Incident Review platform that covers these aspects and allows easy integration between threat hunting detections and triage features. Custom threat hunting algorithms should be able to be integrated in this platform as well, but if not, there is always the possibility of creating a separate Splunk application to handle them. This will be explained further in the last section of this document.
2. Alert Fatigue and Prioritization
A SOC platform must be able to keep up with the threat hunting development and must be able to respond to the triggered notifications. Splunk ES comes with an Incident Response platform, but using it out of the box may not be enough to manage all the notifications because no matter the size of the company, threat hunting may always provide too many notifications compared with the capacity of the incident response team. All those notifications may be important, so they cannot be simply ignored. To solve this problem that could lead to alert fatigue, there are 2 solutions that have to be applied together: prioritization and automation. Automation will be discussed in the next section. As for prioritization, there are 3 strategies that can be applied individually, together or iteratively, as the following schema shows:
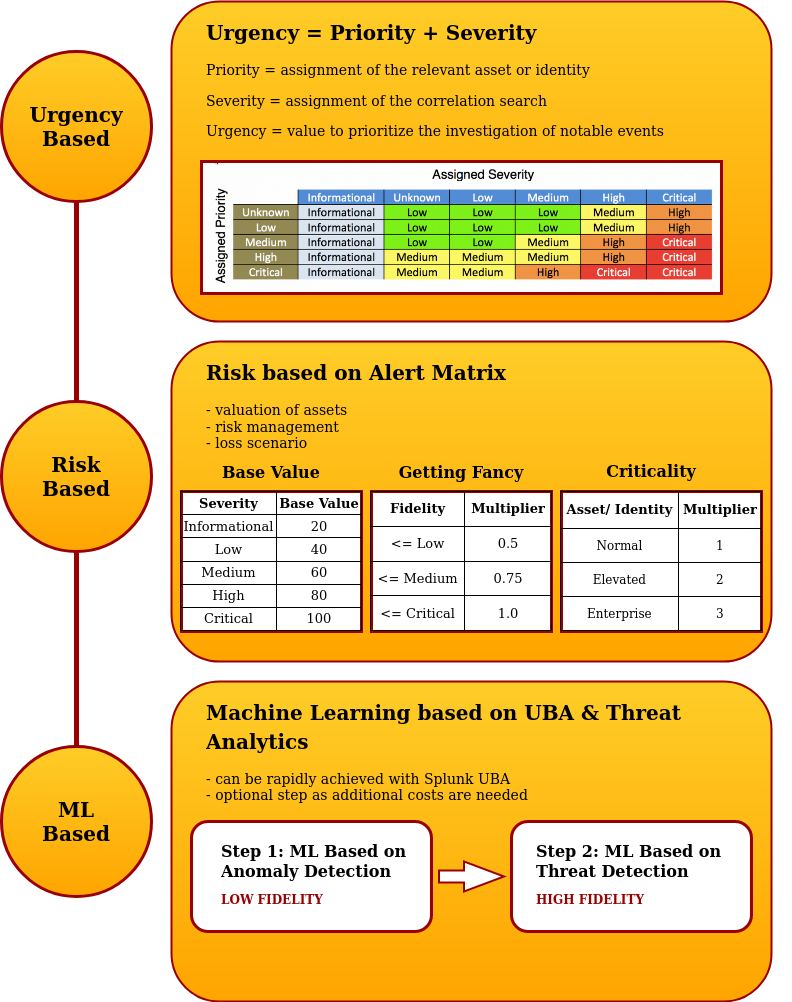
Urgency-based can be implemented using Splunk ES. In the Incident Response page, every detection is categorized based on Urgency. Splunk ES comes with default values for the severity of the alerts ingested from the ESCU and SSE applications. If any custom searches are implemented, a severity value has to be assigned to them. As for the priority value, this one has to be achieved for each of the hosts, using Splunk ES.
Risk-based can be implemented using Splunk ES as well, by assigning a value to each asset and a value to each user, by correlating assets with users and by setting up values for the alerts fidelity and criticality.
While the above 2 methods can be applied with no further costs, the Machine Learning method for prioritization has to be based on User Behavior Analytics, such as the Splunk UBA product, which is not part of our subscriptions. If this module or another UBA product would be bought, the alerts would be correlated with anomaly detection from the UBA in first instance, and then filtered more based on threat detection ML, such as using the MLTK Splunk app, which is free.
3. SOC Platform Iterative Development
The end goal of designing a SOC platform is to be able to get automated detection and automated response in place for a comprehensive set of relevant known threats and to be able to upgrade them for any upcoming threats for the relevant industry. The human element would not be dismissed, but it would be used to triage, respond and then automate only the anomalous and new potential threats rather than manually respond to recurrent alerts.

Such an environment cannot be realistically implemented instantly. It has to be done in an iterative manner, by firstly implementing automated detection, then building up to automated triage, then semiautomated response (verified by humans) and finally automated response. This process can be followed for each alert individually, based on prioritization and alert fatigue or on other metrics such as the frequency of generating false positives, rather than stepping up all the alerts at the same time to next level of automation.
If you have trouble imagining how this would work in real life and how other companies such as corporations implement it, I am sharing with you 2 minutes of catchy Splunk marketing watched during the event: SOCtails – Respond to Security Alerts from Anywhere.
Finally, SOC 5.0 could be implemented as well, if enough resources are in place, which would take advantage of prediction algorithms and large amount of incident data to automate proactive intervention, before the attack has a chance to happen.
4. SOC 1.0 Implementation
A stable SOC 1.0 has to provide automated detection for the relevant attacks and a manageable platform to triage and respond to any events. Everything mentioned previously in this document and all the described tools have to be put together to achieve the following results:
- decide a threat taxonomy, such as MITRE ATT&CK
- decide which APTs and attacks are relevant
- invest in threat intelligence sources, both paid and open-source
- decide a threat hunting process and an incident response process
- work on the relationships, work agreements and communication channels between the threat hunting and incident response teams
- assess the level of alert fatigue and implement prioritization
- smooth the generated alerts by removing the false positives or decreasing them to a minimum
- assess the level of information provided within the notification descriptions, which should contain among other relevant details information on how to triage the alert
- correlate alerts that would otherwise need to be correlated manually before being able to triage them
5. SOC x.0 and Phantom, where x>1
By this point, the company should have a stable SOC platform in place and stable processes for improving the platform and addressing events. From here on, automation will be the main focus to reduce the amount of work a human would have to do and use them instead for more challenging incidents, anomalous behavior and tackle new attacks in the industry.
This can be achieved within 3 SOC iterations:
- SOC 2.0 – automate triage: each event automated by threat hunters should already contain a thorough description on how to triage the event and should contain all the pieces of data needed to make a decision. Based on the description and the fed data, automate the logic decision and notify what happened, how the decision was made, what was the result and what actions need to be taken to resolve the incident.
- SOC 3.0 – human verification for the response: on top of SOC 2.0, automate the actions to be taken to resolve the incident as well, but before running them, wait for a human to verify the right actions are taken, based on the information provided as output from SOC 2.0 and the actions that are going to be applied.
- SOC 4.0 – after a consistent reliable response is received for the automated events, remove the needed for a human to verify the actions and run them immediately (or as decided). These steps can be applied in iterations for bunches of alerts, instead of applying one level of automation to all of them and only then moving to the next one.
Automating Triage can be achieved using Splunk ES for very simple logic decisions, like “if both condition A and B happen, only then raise a notification”. However, most of the cases might need more complex reasoning, eventually grabbing data from different places, that may not be ingested in Splunk for various reasons. In this case, Phantom can be used.
Automating Response, with or without human verification, can be implemented with Phantom, but often needs a prerequisite – infrastructure as code and DevOps quality automation processes. To be able to automate response (such as restoring registry keys being maliciously modified), the automated response modules have to be able to communicate with the infrastructure and direct actions.
6. A little about Phantom
- begin with easy to understand scenarios; they are the best candidate for automation
- choose known procedures; if they are well documented, the return is qualifiable and measurable; if undocumented, white-board it out and then document it in a standardized widely accepted format before automating it
- choose scenarios that are analytically consistent and do not involve cognitive bias
7. Automated Adversary Simulations
The previous sections cover how to automate detection, triage and response, but they do not cover end to end testing. Section I.3 mentions that Atomic Red Team test cases could be implemented for an automated scheduled run and used to test the preventative and detective mechanisms in place and to perform regression testing, in case these ones change. This can be a good start and quite useful for implementing SOC 1.0. Once SOC 1.0 is in place and automated triage and response come into picture together with Phantom, other applications can be used to automate the end to end testing, often called adversary simulation: AttackSimApp (Splunk application), AtomicRedTeamApp (Phantom) and AdversarySimulationPlaybook (Phantom). AttackSimApp is the main application to interact with when running (or scheduling) tests. It allows selection of APTs and tests using SSE, then it connects to AtomicRedTeamApp in Phantom to collect those up to date tests from github, then it runs those tests using the AdversarySimulationPlaybook from within Phantom. After the tests run, the results are collected and published in the Splunk ES application. Here is a schema for this flow:
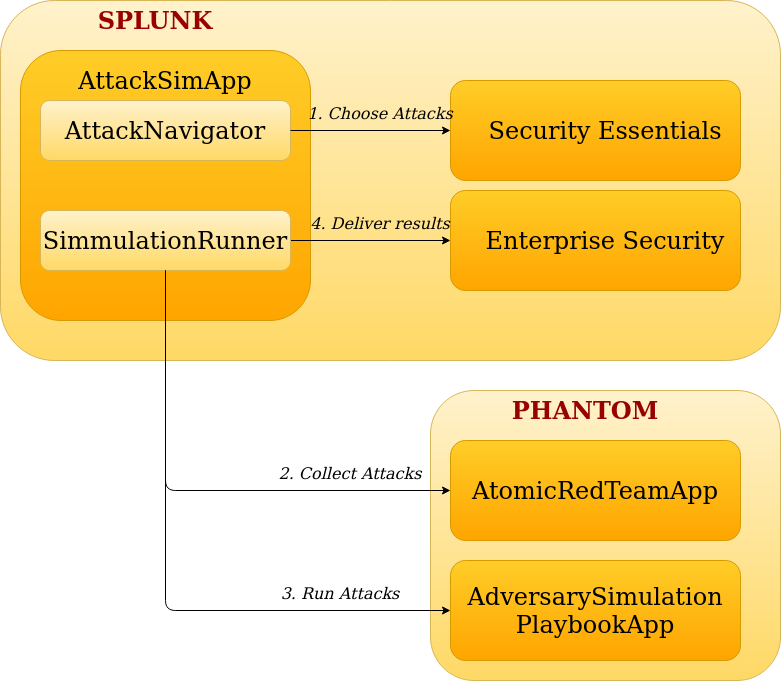
8. Measuring SOC effectiveness
After having a stable process and a stable SOC in place, SOC effectiveness should be measured and optimized, using SMART metrics. Splunk ES comes with a few reports for this purpose, such as ingested data, attacks covered, threat intelligence sources and so on. There is one report useful to address the performance of the incident responding team and it contains the following metrics:
- mean time to detect (dwell time)
- mean time to triage (end to end analysis time)
- mean time to closure (end to end response time)
Additional dashboards and reports could be defined, as presented in the following section.
9. How to build dashboards and reports
Splunk and the integrated applications come with many dashboards, addressing common needs. However, often there is a need to create new dashboards and reports and eventually share them with business management. Instead of modifying existing apps and breaking the compatibility with future updates, the team should create their own applications within Splunk, add there all their custom data, searches, dashboards and reports, share them with the team and continue to improve them to preserve their usability.
Recommended Further Resources
- Splunk Security Essentials 3.0: Driving the content that drives you
- Advanced Threat Hunting and Anomaly Detection with Splunk UBA
- Detecting and Mitigating Insider Threats using MLTK and Enterprise Security
- Add Asset and Identity Data to Splunk Enterprise Security
- Getting Started with Risk-Based Alerting and MITRE
- Modernize and Mature Your SOC with Risk-Based Alerting
- Understand Data Flow in Splunk UBA Machine Learning Toolkit Overview in Splunk Enterprise Security
- Getting Started with Security Automation and Orchestration
- Build Automated Decisions for Incident Response with Splunk Phantom (GE)
- Our Splunk Journey: Implementation Lessons Learned and Playbook Walkthrough (NAB)
- Hacking Your SOEL: SOC Automation and Orchestration
- Start with Investigation in Splunk Phantom Cops & Robbers: Simulating the Adversary to test your Splunk Security Analytics